Scalable architectures with Vue micro frontends: A developer-centric approach

This article is a summary of my talk at VueConf Toronto 2023.
Summary
In this article, we'll explore how to harness the power of Vue.js and micro frontends to create scalable, modular architectures that prioritize the developer experience. We'll unveil practical strategies, best practices, and real-world use-cases that empower developers to build robust, maintainable applications without compromising on agility.
Whether you're a seasoned Vue.js enthusiast or just starting your journey, this article promises valuable insights to enhance your frontend development practices while keeping developer experience at the forefront.
Key takeaways
- Exploring architecture patterns that promote scalability
- Practical tips for optimizing developer workflows, reducing bottlenecks, and fostering collaboration
- Insights into tools, libraries, and Vue-specific techniques that enhance developer productivity in micro frontend environments
- A real-world success story from an organization that has embraced this developer-centric approach and reaped the benefits
Background
Before we dive in to the architecture, let's set the stage with some background information on Kong's UI Engineering teams and the origins of our primary application, Kong Konnect.
Konnect

- Kong Konnect is the unified cloud-native API management platform to optimize any environment. It reduces operational complexity, promotes federated governance, and provides robust security.
- Konnect is a Vue Single-Page Application spanning 10 product areas.
- Specialized Product and Engineering teams collaborate to enhance functionality and introduce new features at a rapid pace. Release early and release often.
Kong UI Engineering
Kong UI Engineering is global and diverse, comprised of over 30 frontend engineers located around the world, collaborating across ten separate teams.
The UI platform at Kong is comprised of a centralized design system and shared Vue component libraries, all consumed by several host applications.
Early on, Konnect's monolithic structure simplified development by making it easier to understand and maintain the codebase. This was initially a good thing as it allowed features to be implemented rapidly by a smaller team of engineers.
As the app grew and the number of contributors began to climb, this architecture was increasingly painful and began causing bottlenecks in many of our workflows. Other non-monolithic architectures can provide much better scalability and maintainability.
The tipping point: The developer experience wasn't great
After somewhat-painfully onboarding several new engineers over the course of a few months, it was apparent our existing architecture had reached the tipping point.
When developer experience (DX) suffers across the board, it's a good sign that it is time for change. Let's walk through some of the issues our engineering team was struggling with.
Poorly-optimized mono repository
The repository was set up as a monorepo of "packages" pieced together through a combination of cross-directory imports and symlinks into a Vue Single Page Application (SPA). The different "packages" were managed via a combination of yarn workspaces and Lerna.
The entire application could easily be impacted by the smallest issue in any one corner of the codebase.
Multiple owners, different concerns
Different teams maintain each area of the application. Each area of the app could define its own set of dependencies, UI layouts, styles, and project settings.
An engineer needing to work across multiple app packages would typically need to delete and reinstall dependencies when changing contexts, and with the nested packages, knowing which package dependencies were resolving from became a guessing game.
With each team being separately responsible for the look and feel within their area of the application, the UI is inconsistent and there are few, if any, standard UI patterns.
Inadequate tooling
Dependency version mismatches, conflicting linting rules, no type safety, multiple continuous integration (CI) pipelines, and various coding "standards" were spread throughout the codebase.
Unrelated test failures
Even with minimal code changes, unrelated test failures were the norm. If engineers chose not to run the tests locally before pushing their code up to the remote, they may not know they broke something for almost an hour.
Long-running feedback loop
Pull Request testing, build, and deploy previews took up to 45 minutes to complete. Ready to merge and release your code to Production? Double it
Automation can be costly
The high number of Pull Requests along with multiple re-runs for failing tests took up resources, meaning engineers would spend time waiting for their code to clear the queue.
Every minute of automation costs the company time and money.
Monolithic architecture metrics
| Metric | |
|---|---|
| Lint, build, unit/component test, deploy preview, and e2e test | 45 min |
| Deploy preview to Prod, e2e test, and release | 45 min |
| GitHub Actions minutes (monthly) | 264K min |
| Pull Requests merged per week | ~112 |
| App deployments per week | ~75 |
You're reading that correctly: 90 minutes from creating a Pull Request to deploying the code to Production. It may as well be forever... and that's if the tests don't fail.
Test failures impact developer experience
Let's pause for a moment and talk about the impact consistently failing tests can have on a distributed group of engineers when all areas of the app are essentially tied together.
The impact isn't isolated just to the quality of code you deliver, but also impacts the developer experience and even the company's bottom line.
Why are flaky tests bad for DX and the company?
Seemingly-unrelated test failures can make the developer experience in any project suffer as they cause frustration and fatigue.
These feelings intensify when you have multiple teams working alongside each other in the same codebase where engineers may only be familiar with the functionality in their own area.
Inevitably, a perception sets in that failing tests are just "flaky."
This leads to quick hacks to get tests to pass and continuous re-runs, which only costs the company more time and money.
How we solved many of our DX issues by moving to a micro frontend architecture
Why micro frontends? Let's talk through some of the advantages a micro frontend architecture provides and how we were able to solve many of our developer experience issues as a result.
Advantages
A developer-optimized monorepo
First, we needed a home for our new architecture.
We initially explored exporting a central core of development tools and settings (think shared configuration files) that would allow for utilizing a common base in multiple, separate repositories. We ultimately decided against this strategy as the learning curve to set up a new repository would require too much assistance for teams to get up and running.
Ultimately, we decided on creating a new pnpm monorepo with unified dependencies, a consistent directory structure contained within app-specific workspaces, and a pre-configured CI/CD pipeline.
pnpm is a drop-in replacement for npm or yarn and provides performant dependency installation and efficient usage of node_modules disk space.
A monorepo that supports a wide array of packages across multiple engineering teams will accumulate a lot of dependencies over time. Performance and efficiency when handling these dependencies is critical.
Autonomous, team-based development
Each app is able to be developed, tested, and deployed independently, and in parallel. Teams can release new features and enhancements and need not be concerned with other apps.
Local development allows for accessing external micro frontends via proxy. This means you have full access to the entire app ecosystem while only needing to run the app you are currently working on.
Reduced bottlenecks
Repeatable and extendable patterns for each separate application enable teams to build rapidly with minimal support.
Context switching for contributors becomes less of a burden as standards and structures are the same between apps.
Documentation is key and allows most teams to self-serve when it comes to adding features, extending testing frameworks, or even spinning up new micro frontends.
An integrated ts-node CLI allows any engineer to easily scaffold a new application with the desired setup.
Scalable architecture
As Kong's UI platform grows, our micro frontend architecture easily scales by allowing us to introduce additional top-level apps as needed.
With the integrated CLI to spin up a new app, we can ensure that each application is initially organized in a familiar pattern and adheres to our common configuration settings.
A centralized core: Downstream apps "just work"
Rather than duplicating code across individual applications, core logic and a standard UI layout is provided by a shared AppShell component.
A core component can be updated in one place and can be independently tested prior to release, meaning downstream apps don't have to test core functionality.
Testing is finally easy
Vitest (for unit and component tests) and Cypress (for end-to-end tests) are pre-configured to allow for a standard testing pattern.
Our shared test configuration also allows each individual app to configure and extend its testing strategy as needed without impacting the other apps in the repo.
Shared test commands are available globally, meaning tests can be written the same across the entire monorepo.
Shared tooling that doesn't get in the way
Shared TypeScript, ESLint, and other configurations are put in place to enforce consistent coding standards, type safety, and code quality.
Some of our engineers may not be familiar with setting up a new project or the proper configuration settings. By utilizing shared configurations, we can easily change the settings for all apps in one place and remove the barrier to entry when starting a new project.
Git hooks
Pre-push hooks enforce linting, type checking, and commit format before the code is pushed in order to prevent running CI workflows for code that does not conform to our standards.
(If you're interested, we utilize lefthook to manage and run our git hooks.)
Splitting up the monolith
Engineering and Product teams at Kong are generally organized by top-level app, so it was natural for the new architecture to follow the same pattern.
We split the application vertically by product domain, meaning each primary sidebar item in the application corresponds to a separate micro frontend.
This structure allows for autonomous, team-based development, where each individual team has full ownership of the business logic within their domain.
Monorepo Structure
.github/ # Shared CI/CD workflows
apps/ # Each app is a pnpm workspace
├── auth/
├── analytics/
├── api-products/
├── dev-portal/
├── gateway-manager/
├── mesh-manager/
├── organization/
└── servicehub/
cypress/ # Global Cypress config and shared utils (commands, etc.)
cypress.config.ts
docs/ # Docs for creating a new app, "How to...", etc.
.eslintrc.cjs # Global ESLint configuration
lefthook.yaml # Manage git hooks
package.json # Shared devDependencies, etc.
tsconfig.json # Extendable TypeScript config
vitest.config.ts # Global Vitest config
vite.config.shared.ts # Extendable Vite config
Individual app structure
apps/
└── organization/ # App code is completely isolated from the other apps
├── cypress/ # App-specific Cypress E2E tests
│ ├── fixtures/
│ ├── specs/ # Tests are organized by type
│ │ ├── regression/
│ │ └── smoke/
│ ├── support/
│ ├── cypress.regression.config.ts # Extends the root cypress.config.ts
│ └── cypress.smoke.config.ts
├── src/ # Standard structure for app components, composables, pages, etc.
├── package.json # App-specific dependencies, etc.
├── tsconfig.json # Extends the root tsconfig.json
└── vite.config.ts # Extends the root vite.config.shared.ts
The Core AppShell

Global UI
All micro frontend applications within Konnect must implement the same global UI. The global UI includes the primary sidebar navigation, navbar items, and main content area.
Rather than apps having to replicate the layout and have knowledge of the other micro frontends that exist within the Konnect ecosystem, we created a shared AppShell component that all micro frontends utilize within their app's root component.
Each team then only needs to be concerned with the logic and functionality within their respective micro frontend, illustrated below by the highlighted area.

As an example, while the Konnect application's primary sidebar navigation items are global, each micro frontend provides its own secondary navigation items as needed via a prop passed to the AppShell component.
External apps do not need any knowledge or context of what exists within other individual apps, so they are free to add features and pages as the product area is enhanced.
Shared core logic
Since the AppShell component is required for all Konnect micro frontend applications, it can also take care of initializing the core app logic required to operate within the Konnect ecosystem.
This includes:
- Authentication
- Retrieving and managing user session data
- Authorization and permissions fetching and evaluation
- Managing the active Konnect region and ensuring the correct, region-specific APIs are utilized appropriately.
- Route configuration (to ensure all apps follow the path-based, region-specific URL structure)
- Global notification and error UI, as well as automated error reporting.
This means when the AppShell is finished loading and the host app's content is shown, the host application can assume the user has a valid session and all necessary data to proceed within the app.
Let's take a look at the host application's root component:
<template>
<!-- The host app injects its content via an internal `<router-view />` -->
<AppShell
:sidebar-items="sidebarItems"
:loading="appLoading"
:error="appError"
@ready="appShellReady"
@update:session="(data: SessionData) => syncSessionData(data)"
/>
</template>
<script setup lang="ts">
const sidebarItems = computed(
(): SidebarSecondaryItem => ({
// Link the provided secondary items to their top-level parent
parentKey: 'api-products',
// Conditionally provide sidebar items
items:
route.params.service &&
[
/** {...items...} */
],
}),
)
</script>
Referencing the code shown above:
- The sidebar items are provided by a reactive variable, controlled by the host app, to inject the secondary sidebar navigation items
- The loading and error states are initially handled by the
AppShellwhile fetching the required data, then, control is "released" to the host app via props - A
@readyevent is fired when theAppShellhas completed initialization (e.g. session setup, permissions, feature flags, etc.) - An
@update:sessionevent is fired whenever the underlying session data is updated from the shell; this allows the host app to have a reactive reference to the live session data
Tradeoffs
Moving to a micro frontend architecture also required coming to terms with some tradeoffs. Keep in mind, tradeoffs are subjective.
If you're thinking of moving to a similar architecture you'll want to evaluate the tradeoffs you encounter, with respect to your own project and determine the path forward.
Moving apps to the new architecture requires tracking in-progress feature work
Maintaining two versions of the code, for a period, was definitely the largest pain-point in the process for our teams.
The best advice I can offer is to thoroughly plan for the transition, and schedule the move during a time when the product area may have some inherit downtime (e.g. between major feature work releases).
Taking the time to evaluate the code that needs to be moved will allow your team to understand how different areas of the codebase are related and if they are interdependent on each other.
Apps are still housed in a monorepo
In our evaluation, things are subjectively better due to code quality and other developer experience improvements.
Keeping apps within the monorepo also allowed for easier context switching for engineers that typically work on cross-team projects.
Secondary navigation items are not accessible without a user first navigating to the app
To view the secondary navigation items in the sidebar for any given app, you first have to click the primary navigation item and wait for the corresponding host application to hydrate.
In our current iteration of the architecture, this behavior is actually considered a "feature" as it allows each app the freedom to change its structure without external apps needing to care.
Want to add a new child page? Do it! The other primary apps are completely unaffected.
Navigating between micro frontends requires a full page reload
Since each app is essentially a separate single-page application (SPA), a full page load is required when moving between micro frontend applications.
It's fine, I promise.
To provide the user with a relatively seamless transition between apps, we wrote a Vite plugin that injects a static HTML loading template into the host app's index.html file during the build.
<body>
<div id="app">
<!-- Static HTML loading template -->
</div>
<script type="module" src="/src/main.ts"></script>
</body>
The template emulates the same global layout provided from the AppShell component including some user-specific data gathered from web storage.
When the host application begins hydrating, the static template is removed and is replaced with the live AppShell component.
We also implemented a caching mechanism on the client-side to persist critical session data request responses. This allows us to initially fetch the user's session data upon successful authentication, and then quickly rehydrate the data needed for a user's session from web storage when navigating between micro frontends. Once the next micro frontend hydrates, we do a separate request in the background to update the cache, ensuring we always have up-to-date information on the current user.
It's all about perception
This technique is similar to what my hometown airport does when the last flight of the night lands.
The airport instructs the plane to park at the gate furthest from the baggage claim area. By the time you deplane and walk through the terminal all the way across the airport to the baggage claim, your checked bags have already been unloaded and are waiting for you.
Did the crew sprint across the tarmac to sure I didn't have to wait for my bags?
Nope. Since I had to walk all the way through the terminal, it gave me the perception that the bags arrived almost as soon as I got there even though the timing was the same. It's all about perception.
How we build and deploy
With the new architecture, our build and deploy workflows are powered by GitHub Actions along with S3 and CloudFront.
Build and deploy via GitHub Actions
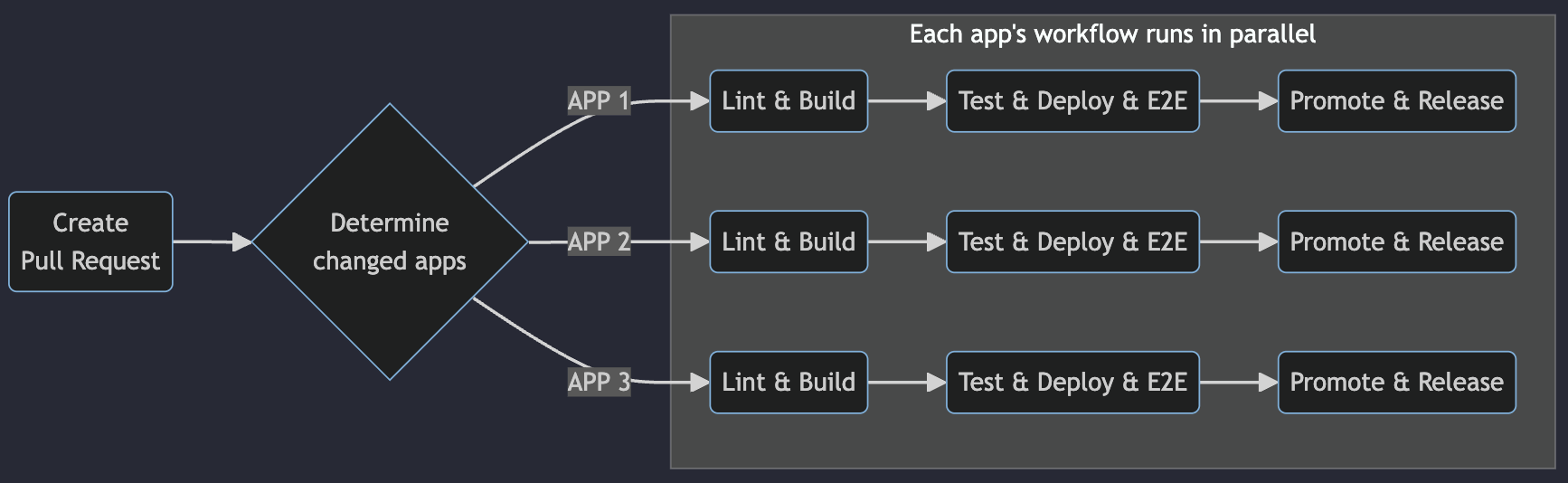
Concurrent workflows for each individual application decrease the time to release.
Upload assets to S3
We maintain two separate buckets in S3:
A Preview bucket for deploy previews in Dev and Prod environments, and a Release bucket for Production deploys.
The Release bucket, only for production assets, is replicated across multiple regions to allow for lower latency and safety.
Each bucket is organized so that each app's assets are in their own folder (object), and buckets are essentially origins for the S3 distributions (e.g. S3 release bucket is the origin for the S3 release distribution).
Sourcemaps are also uploaded to our error monitoring service for stack traces, etc.
Deploy stages
We then deploy the assets in two stages:
Preview
The Preview stage allows a full end-to-end test suite to run in the preview environment before reaching production. If any issues are encountered during the preview deploy or testing, it blocks the production release.
In the Preview stage, we upload into the Preview bucket via sub-directories based on the corresponding Pull Request number, (e.g. /organization/pr-22/index.html) instead of storing assets at the root.
This allows us to utilize these directories for CloudFront origins for Pull Request deploy previews which are useful to allow Product and Design teams to review functionality, before merge, without running the code locally.
Promote
Once the production testing pipeline completes, we simply copy the S3 Preview bundle to our S3 Release bucket and the app changes go live.
Invalidate old assets
Assets are typically fingerprinted so that new release bundles are automatically fetched from the browser at runtime.
For any non-fingerprinted assets, the cache is invalidated on release to force any subsequent browser requests to download the new asset bundles.
Emergency deploys
A backdoor emergency release workflow allows pushing asset bundles directly to S3 if the deploy pipeline is blocked (e.g. failing tests) or quick fixes are needed in production.
Serving apps via CloudFront
Request routing via CloudFront functions
A custom CloudFront function utilizes the hostname and request path when the browser request is received in order to determine the proper S3 bucket and asset folder to serve.
As an example, if we visit /global/organization/* CloudFront will evaluate the function and return a request URI of /organization/index.html which will automatically load the Organization app's entry file.
This deploy strategy also allows for Pull Request-based deploy preview URLs and proxying external apps to the remote environment while developing a single app locally.
We purposefully chose not to use lambda functions in our CloudFront implementation as CloudFront functions are much cheaper and run on the Edge network itself, making them extremely faster.
It's fast out here on the Edge
CloudFront stores a cache of the assets on the Edge network after the initial request, making subsequent requests blazingly fast.
If an asset is requested and not found in the cache, CloudFront automatically grabs it from the S3 bucket and then adds it to the cache so that the next request for the asset is served directly from the Edge network.
Global availability
CloudFront is global, meaning it will serve assets to the user from the closest node of the Edge network and automatically re-route traffic if it detects an issue.
Routing browser requests through CloudFront also allows us to easily override requests in the case of planned downtime, e.g. redirecting to a maintenance or status page.
Results
Our goal was to begin splitting up the monolith and enable teams to operate independently while greatly improving the overall DX.
Let's take a look at how we did.
Micro frontend architecture metrics
| Metric | Before | After |
|---|---|---|
| Lint, build, unit/component test, deploy preview, and e2e test | 45 min | 6 min |
| Deploy preview to Prod, e2e test, and release | 45 min | 7 min |
| GitHub Actions minutes (monthly) | 264k min | 1.8K min |
| Pull Requests merged per week | ~112 | ~220 |
| App deployments per week | ~75 | ~135 |
Referencing the data above:
- We refactored the tests and deploy previews to run in parallel, significantly decreasing the overall timings.
- We were able to tie the decrease in GitHub Actions minutes used for the frontend repos to the reduced number of re-runs.
- Shorter feedback loops and better code quality allows for a more rapid pace of development.
What did we accomplish?
- Created a developer-optimized monorepo
- Enabled autonomous, team-based development and reduced bottlenecks
- Consolidated core functionality into a shared component
- Implemented tooling that enforces better code quality while saving time and money
- Created reusable testing patterns and configurations
- Shortened the feedback loop and time to release
- Created a scalable architecture that will support an evolving UI platform
We did a lot of research and proof-of-concept iterations over the course of several months and determined this architecture was the best "next step" for the evolution of Kong's UI platform.
This micro frontend architecture addresses many of the problems we were encountering, and has significantly improved the developer experience for our engineers.
Remember, changing architectures is a big deal.
Rather than attempting to fix all of our problems at once, we chose to address the heavy-hitters in smaller, manageable iterations to move us in the right direction.
Once each app is migrated to the new architecture, we will continue to improve the solution for the next evolution of the platform.
If you have questions or are curious about more in-depth info, feel free to reach out on Twitter/X @adamdehaven.